Quickstart
Remote sensing data can be used for many purposes - for vegetation, climate, soil and human impact analysis. RSP can prepare raw remote sensing data for analysis.
Here is an example of some features that RSP provides. We will perform a simple task - train a semantic segmentation model that will predict landcover class using Sentinel-2 and DEM data.
First, we need to preprocess data. We preprocess Sentinel-2 images and merge them into a mosaic, then we calculate NDVI of that Sentinel-2 mosaic. We also merge DEM images into mosaic, match it to the same resolution and projection as Sentinel-2 data and normalize its values. We rasterize landcover shape file and match it to the same resolution and projection as Sentinel-2 data.
Then we prepare data to semantic segmentation model training. We use Sentinel-2 and DEM data as training data and landcover data as a target variable. We cut our data into small tiles and split it into train, validation and test subsets. Then we train and test UperNet model that predicts landcover based on Sentinel-2 and DEM data. Finally, we use this model to create a landcover map.
Importing RSP
Here we import Remote Sensing Processor
import remote_sensing_processor as rsp
Sentinel-2 preprocessing
We have 6 Sentinel-2 images that cover our region of interest.
>>> from glob import glob
>>> sentinel2_imgs = glob('/home/rsp_test/sentinels/*.zip')
>>> print(sentinel2_imgs)
['/home/rsp_test/sentinels/L1C_T42VWR_A032192_20210821T064626.zip',
'/home/rsp_test/sentinels/L1C_T42WXS_A032192_20210821T064626.zip',
'/home/rsp_test/sentinels/L1C_T43VCL_A032192_20210821T064626.zip',
'/home/rsp_test/sentinels/L1C_T43VDK_A031391_20210626T063027.zip',
'/home/rsp_test/sentinels/L1C_T43VDL_A023312_20210823T063624.zip',
'/home/rsp_test/sentinels/L1C_T43VDL_A031577_20210709T064041.zip']
We need to preprocess these images. Preprocessing includes converting L1 products to L2, superresolution for 20 and 60m bands and cloud masking.
First step of preprocessing is converting L1 raw product to atmospherically corrected L2 product. It is done with Sen2Cor algorythm.

Image from here
Second step is upscaling 20-m and 60-m bands to 10-m resolution with superresolution model.

Image from here
Final step is cloud masking. It is done with cloud mask file from sentinel image, surface type map generated during Sen2Cor L2 product generation and with band 1 and 9 filters.
Sentinel image before masking

Sentinel image after cloud masking.

sentinel2 function can take list of images as input and process all of them one by one.
By default sen2cor parameter is True, upscale is superres and cloud_mask is True, so the function will use sen2cor, perform superresolution and mask clouds by default.
Machine learning models usually work best with normalized data, so we need to set normalize parameter to True.
>>> output_sentinels = rsp.sentinel2(sentinel2_imgs, normalize=True)
Preprocessing of /home/rsp_test/sentinels/L1C_T42VWR_A032192_20210821T064626.zip completed
Preprocessing of /home/rsp_test/sentinels/L1C_T42WXS_A032192_20210821T064626.zip completed
Preprocessing of /home/rsp_test/sentinels/L1C_T43VCL_A032192_20210821T064626.zip completed
Preprocessing of /home/rsp_test/sentinels/L1C_T43VDK_A031391_20210626T063027.zip completed
Preprocessing of /home/rsp_test/sentinels/L1C_T43VDL_A023312_20210823T063624.zip completed
Preprocessing of /home/rsp_test/sentinels/L1C_T43VDL_A031577_20210709T064041.zip completed
>>> print(output_sentinels)
['/home/rsp_test/sentinels/L1C_T42VWR_A032192_20210821T064626/',
'/home/rsp_test/sentinels/L1C_T42WXS_A032192_20210821T064626/',
'/home/rsp_test/sentinels/L1C_T43VCL_A032192_20210821T064626/',
'/home/rsp_test/sentinels/L1C_T43VDK_A031391_20210626T063027/',
'/home/rsp_test/sentinels/L1C_T43VDL_A023312_20210823T063624/',
'/home/rsp_test/sentinels/L1C_T43VDL_A031577_20210709T064041/']
Function returns list of folders with preprocessed images.
Merging Sentinel-2 images
In this stage preprocessed Sentinel-2 images are being merged into one mosaic. This function can merge not only single-band images, but also multi-band imagery like Sentinel-2. clip argument is a path to a file with a border of our region of interest that is used to clip data, crs is a CRS we need, and nodata_order is to merge images in order from images with less nodata values on top (they are usually clear) to images with most nodata on bottom (they usually are most distorted and cloudy).
>>> border = '/home/rsp_test/border.gpkg'
>>> mosaic_sentinel = rsp.mosaic(
... output_sentinels,
... '/home/rsp_test/mosaics/sentinel/',
... clip=border,
... crs='EPSG:4326',
... nodata_order=True,
... )
Processing completed
>>> print(mosaic_sentinel)
['/home/rsp_test/mosaics/sentinel/B1.tif',
'/home/rsp_test/mosaics/sentinel/B2.tif',
'/home/rsp_test/mosaics/sentinel/B3.tif',
'/home/rsp_test/mosaics/sentinel/B4.tif',
'/home/rsp_test/mosaics/sentinel/B5.tif',
'/home/rsp_test/mosaics/sentinel/B6.tif',
'/home/rsp_test/mosaics/sentinel/B7.tif',
'/home/rsp_test/mosaics/sentinel/B8.tif',
'/home/rsp_test/mosaics/sentinel/B8A.tif',
'/home/rsp_test/mosaics/sentinel/B9.tif',
'/home/rsp_test/mosaics/sentinel/B11.tif',
'/home/rsp_test/mosaics/sentinel/B12.tif']
The function returns list of band mosaics.
Calculating NDVI for sentinel-2 mosaic
Normalized difference function can automatically select bands for calculating NDVI based on Sentinel-2 image, we can just give it index name and a folder where bands are stored.
>>> ndvi = rsp.calculate_index('NDVI', '/home/rsp_test/mosaics/sentinel/')
>>> print(ndvi)
'/home/rsp_test/mosaics/sentinel/NDVI.tif'
Merging DEM images
We also need to merge ASTER GDEM images into one mosaic.
>>> dems = glob('/home/rsp_test/dem/*.tif')
>>> print(dems)
['/home/rsp_test/aster_gdem/N63E069_FABDEM_V1-0.tif',
'/home/rsp_test/aster_gdem/N63E070_FABDEM_V1-0.tif',
'/home/rsp_test/aster_gdem/N63E071_FABDEM_V1-0.tif',
'/home/rsp_test/aster_gdem/N64E069_FABDEM_V1-0.tif',
'/home/rsp_test/aster_gdem/N64E070_FABDEM_V1-0.tif']
For machine learning we need our data sources to have the same CRS and the same resolution. We can match different rasters by setting reference_raster parameter. Here we set one of the Sentinel band mosaics as a reference raster.
>>> mosaic_dem = rsp.mosaic(
... dems,
... '/home/rsp_test/mosaics/dem/',
... clip=border,
... reference_raster='/home/rsp_test/mosaics/sentinel/B1.tif',
... nodata=0,
... )
Processing completed
>>> print(mosaic_dem)
['/home/rsp_test/mosaics/dem/N63E069_FABDEM_V1-0_mosaic.tif']
Normalizing DEM mosaics
Data normalization usually can significantly improve convergence time and accuracy of neural networks, so we will normalize our data. Min/Max normalization will convert data values to range from 0 to 1. We need to set minimum value that will be 0 in normalized data and maximum value that will be 1. We know that heights in our DEM are higher than 100 m and lower than 1000 m, so we will set these values as minimum and maximum.
>>> rsp.normalize(mosaic_dem[0], mosaic_dem[0], 100, 1000)
Rasterizing vector landcover data
We have a custom landcover map that we want to use to train a model. We need to rasterize it. We want it to match the resolution and CRS of other data sources, so we set one of Sentinel bands as a reference_raster. Vector files usually contain several attributes. We want to vectorize type attribute, so we set value = "type".
>>> landcover_shp = '/home/rsp_test/landcover/types.shp'
>>> landcover = '/home/rsp_test/landcover/types.tif'
>>> rsp.rasterize(
... landcover_shp,
... reference_raster='/home/rsp_test/mosaics/sentinel/B1.tif',
... value="type",
... output_file=landcover,
... )
Cutting data to tiles
The goal of this tutorial is to create a model that predict land cover classes (target variable) based on Sentinel-2 and ASTER GDEM imagery (training data). We will use Convolutional Neural Network (CNN) for this task. CNN takes tiles of same size as input and process them one by one or unite them into mini-batches.
Here we define x data (that will be used by CNN as input training data) and y data (that will be used as target variable).
>>> x = mosaic_sentinel + mosaic_dem
>>> y = landcover
We will cut Sentinel and DEM (x) and landcover (y) data to 256x256 px tiles (tile_size = 256). To have lower bias we will random shuffe tiles (shuffle = True). To evaluate model performance on a data that was not used in model training we will split data into train, validation and test subsets in proportion 3 to 1 to 1 (split = [3, 1, 1]).
The function returns x dataset and list of y datasets (because it can handle several target variables).
>>> x_tiles, y_tiles = rsp.segmentation.generate_tiles(
... x,
... y,
... tile_size=256,
... shuffle=True,
... split=[3, 1, 1],
... split_names=['train', 'val', 'test'],
... )
There are 3000 tiles in train set and 1000 tiles in both validation and test sets.
>>> print(len(x_tiles.tiles[0]))
3000
>>> print(len(x_tiles.tiles[1]))
1000
>>> print(len(x_tiles.tiles[2]))
1000
>>> print(len(y_tiles[0].tiles[0]))
3000
>>> print(len(y_tiles[0].tiles[1]))
1000
>>> print(len(y_tiles[0].tiles[2]))
1000
Samples are shuffled, task is classification.
>>> print(len(x_tiles.tiles))
5000
>>> print(x_tiles.samples[:5])
[1876, 684, 25, 7916, 1347]
>>> print(y_tiles[0].classification)
True
There are 11 classes in the data, their values are [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100].
>>> print(y_tiles[0].num_classes)
11
>>> print(y_tiles[0].classes)
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
>>> print(x_tiles.rio.nodata)
0
>>> print(y_tiles[0].rio.nodata)
0
Training UperNet CNN
Here we are training UperNet CNN that predicts landcover class based on sentinel imagery.
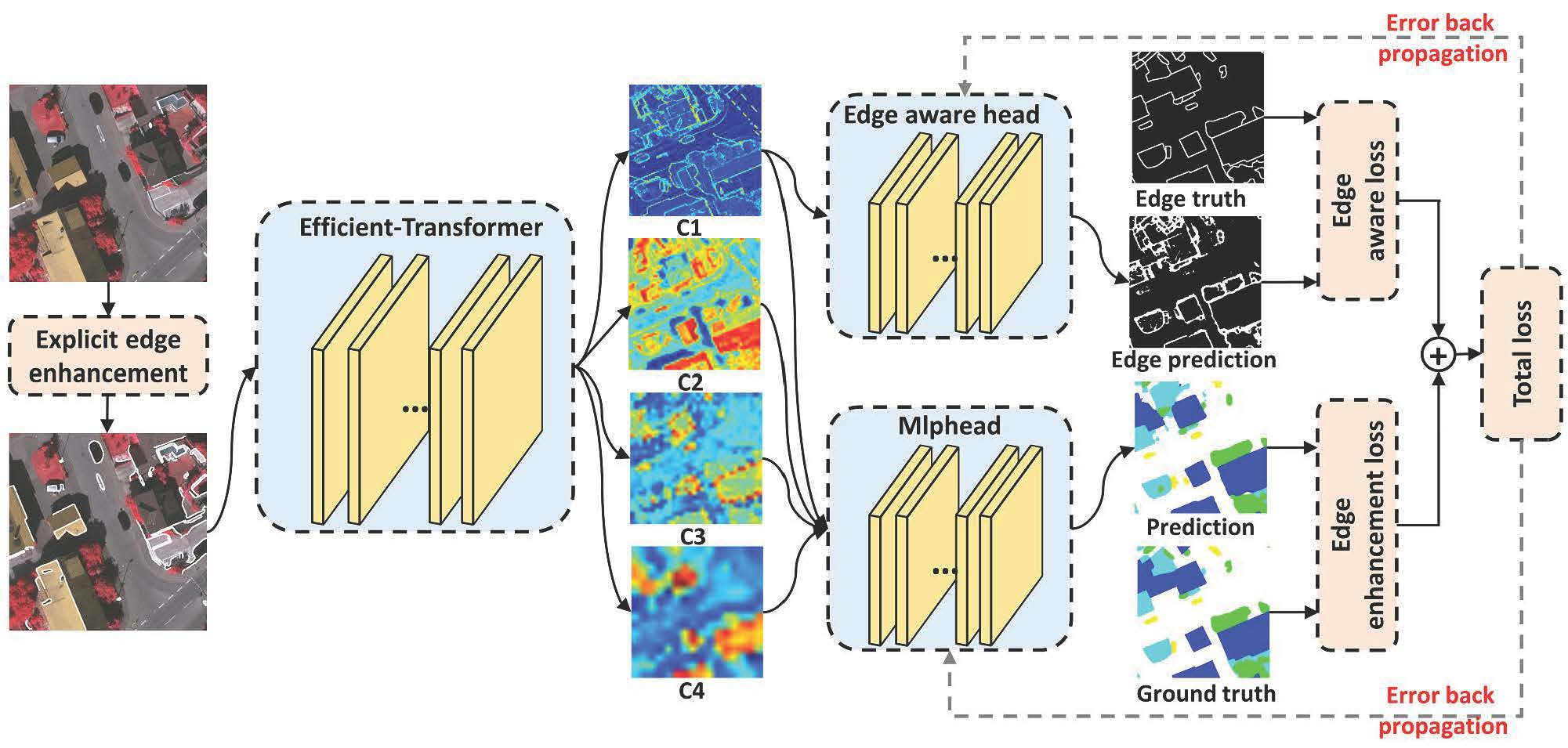
First, we need to set up train and validation datasets. Each dataset is a list of 3 elements: training data (x): file path or xarray.DataArray, target variable (y): file path or xarray.DataArray, split_names: split name defined in generate_tiles or list of split names or ‘all’ if you need to use the whole dataset. You can provide a list of datasets to train model on multiple datasets.
>>> train_ds = [x_tiles, y_tiles[0], 'train']
>>> val_ds = [x_tiles, y_tiles[0], 'val']
We will use the UperNet model architecture (model == 'UperNet') with ConvNeXTV2 backbone (backbone = 'ConvNeXTV2'). Model will be saved to /home/rsp_test/model/upernet.ckpt and could be used later for testing and prediction. Model will be trained for 100 epochs (epochs = 100) with batch size of 32 tiles (batch_size = 32).
>>> model = rsp.segmentation.train(
... train_ds,
... val_ds,
... model='UperNet',
... backbone='ConvNeXTV2',
... model_file='/home/rsp_test/model/upernet.ckpt',
... epochs=100,
... )
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-----------------------------------------------------------
0 | model | UperNetForSemanticSegmentation | 59.8 M
1 | loss_fn | CrossEntropyLoss | 0
-----------------------------------------------------------
59.8 M Trainable params
0 Non-trainable params
59.8 M Total params
239.395 Total estimated model params size (MB)
Epoch 99: 100% #############################################
223/223 [1:56:20<00:00, 31.30s/it, v_num=54, train_loss_step=0.326, train_acc_step=0.871, train_auroc_step=0.796, train_iou_step=0.655,
val_loss_step=0.324, val_acc_step=0.869, val_auroc_step=0.620, val_iou_step=0.678,
val_loss_epoch=0.334, val_acc_epoch=0.807, val_auroc_epoch=0.795, val_iou_epoch=0.688,
train_loss_epoch=0.349, train_acc_epoch=0.842, train_auroc_epoch=0.797, train_iou_epoch=0.648]
`Trainer.fit` stopped: `max_epochs=100` reached.
Then we need to test model performance on test data.
>>> test_ds = [x_tiles, y_tiles[0], 'test']
>>> rsp.segmentation.test(test_ds, model=model)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test_acc_epoch │ 0.8231202960014343 │
│ test_auroc_epoch │ 0.7588028311729431 │
│ test_iou_epoch │ 0.69323649406433105 │
│ test_loss_epoch │ 0.40799811482429504 │
│ test_precision_epoch │ 0.8231202960014343 │
│ test_recall_epoch │ 0.8231202960014343 │
└───────────────────────────┴───────────────────────────┘
Mapping predictions
When we finished training a model, we can use it to create a landcover map based on its predictions. We need to define data that will be used for prediction (it is x_tiles), target variable data that was used to train the model (it is y_tiles[0]) reference raster to get transform and CRS from (it is raster with our landcover data), model that will be used for predictions (it is out UperNet model) and a path where to write output map.
>>> reference = landcover
>>> output_map = '/home/rsp_test/prediction.tif'
>>> rsp.segmentation.generate_map(x_tiles, y_tiles[0], reference, model, output_map)
Predicting: 100% #################### 372/372 [32:16, 1.6s/it]